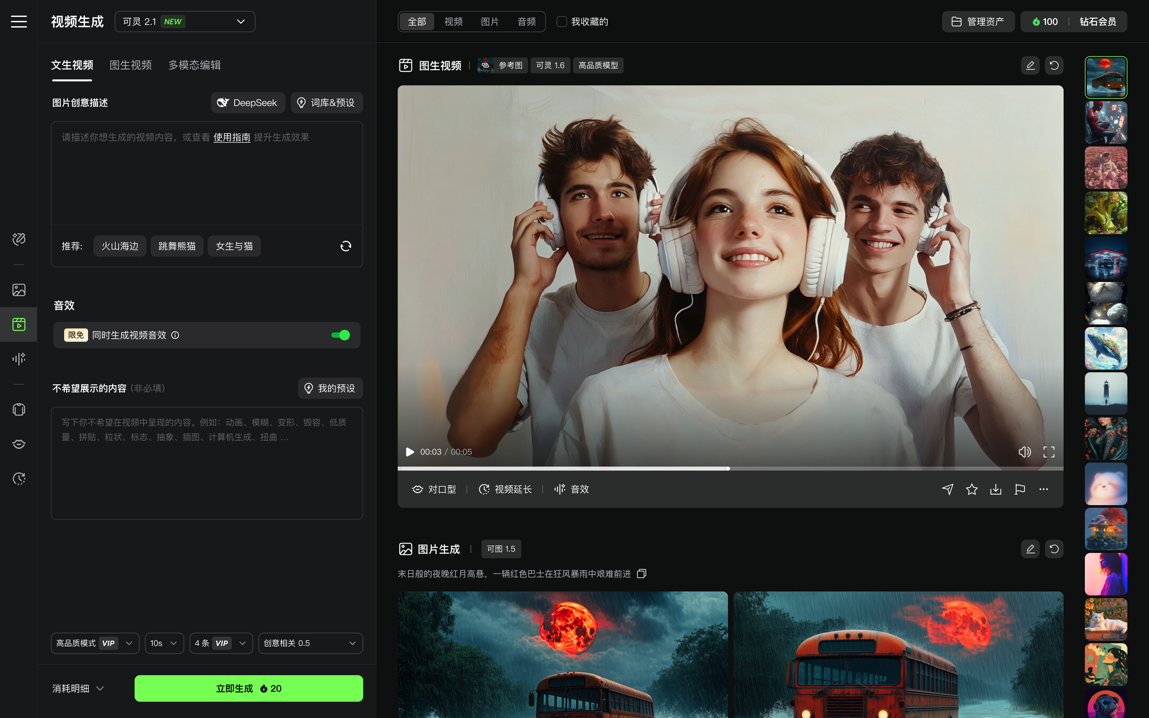
6月27日,可靈AI宣布全系列視頻模型上線“視頻音效”功能,用戶在使用可靈AI進行視頻創作時,不僅能獲得高質量的視頻畫面,更能體驗到與視頻精準匹配、富有空間感的立體聲音效,真正實現“所見即所聽”的沉浸式體驗。目前,該功能已無縫集成至文生視頻、圖生視頻、多模態編輯等多種創作模式中,并限時免費開放。
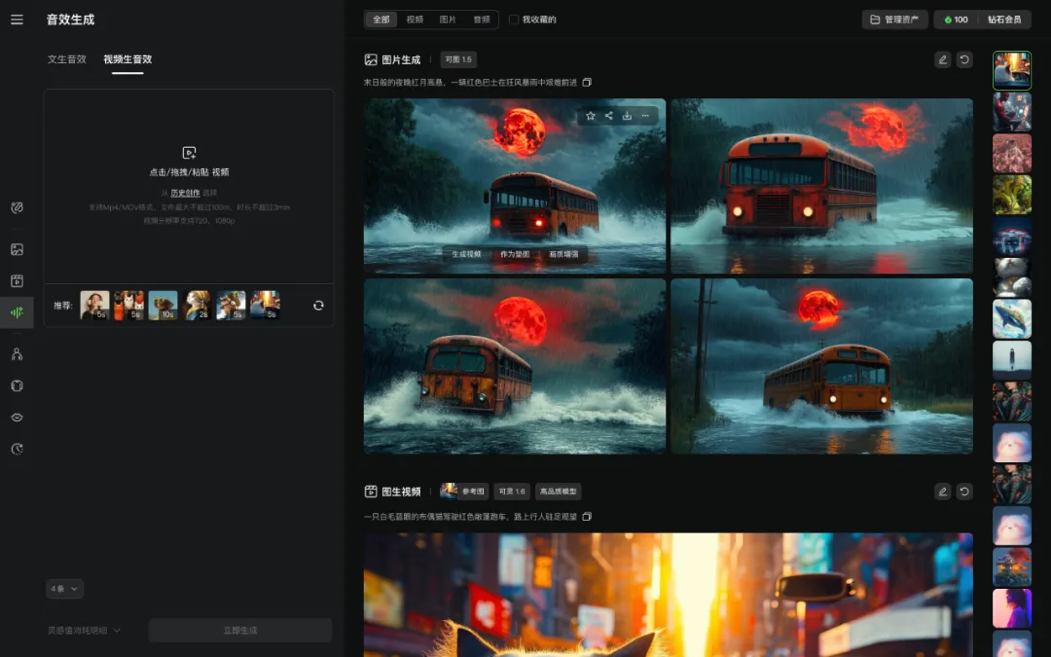
與此同時,平臺原有的“音效生成”也進一步升級,新增“視頻生音效”功能。用戶現在不僅可以通過文本生成音效,更可以直接上傳本地視頻,或選用在可靈平臺創作的歷史視頻,一鍵為無聲的畫面匹配上語義契合、節奏同步的音效,自動適配動作、環境、氛圍等多種場景,極大地提升了視頻內容的表現力和沉浸感,有效降低了創作者在音頻后期制作上的時間與技術成本。
從實際效果來看,可靈AI的音效功能在多個典型案例中展現了極高的音畫同步精度和極佳的空間聽感。例如,在生成“嬰兒在活潑地笑”的視頻片段中,模型不僅還原了嬰兒清亮的笑聲,甚至連嬰兒笑容間隙短促的吸氣聲都完美捕捉,與畫面中肉嘟嘟臉頰的起伏動作精準匹配,其富有空間感的立體聲效果,讓整個畫面的溫馨感與生命力撲面而來。
在另一段山體滑坡導致巨石砸中汽車的視頻中,系統自動生成了金屬扭曲斷裂聲、石塊飛濺與塵土揚起的細節音效,聲音定位清晰、動態層次豐富,提升了整體災難場景的視覺沖擊力與沉浸感。

據悉,上述功能的實現,依托于可靈AI自主研發的多模態視頻生音效模型——Kling-Foley。Kling-Foley 支持基于視頻內容與可選文本提示自動生成與視頻畫面語義相關、時間同步的高質量立體聲音頻,涵蓋音效、背景音樂等多種類型聲音內容。它支持生成任意時長的音頻內容,還具備立體聲渲染的能力,支持空間定向的聲源建模和渲染。
今年3月,可靈AI首次推出AI音效功能,用戶可通過輸入文本生成相應的環境音或動作音,并可進一步結合平臺生成的視頻進行語義理解與自動匹配。隨后,在可靈2.1模型中正式加入了視頻音效功能,在生成視頻的同時,系統也會自動生成與之匹配的音效,增強了整體視聽體驗。隨著視頻音效生成技術的成熟落地,將進一步釋放可靈AI在廣告創意、影視、短視頻、游戲等內容等領域的發展潛力。















